CNNによる二値画像AutoEncoder
PyTorch CNNによる二値画像AutoEncoderの解説
二値画像(白黒画像)を扱うAutoEncoderのサンプルコードを解説します。
完全なサンプルコード
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
# デバイスの設定
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# MPSが利用可能かチェック
if torch.backends.mps.is_available():
device = torch.device("mps")
# ハイパーパラメータ
BATCH_SIZE = 128
LEARNING_RATE = 0.001
EPOCHS = 3
LATENT_DIM = 32 # 潜在空間の次元数
# データの準備(MNISTを例に使用)
transform = transforms.Compose([
transforms.ToTensor(),
#transforms.Normalize((0.5,), (0.5,)) # -1~1の範囲に正規化
transforms.Lambda(lambda x: (x > 0.5).float()) # 二値化
])
train_dataset = datasets.MNIST(
root='~/.pytorch/data',
train=True,
download=True,
transform=transform
)
train_loader = DataLoader(
train_dataset,
batch_size=BATCH_SIZE,
shuffle=True
)
# Encoderの定義
class Encoder(nn.Module):
def __init__(self, latent_dim):
super(Encoder, self).__init__()
# 畳み込み層
self.conv_layers = nn.Sequential(
# 入力: 1x28x28
nn.Conv2d(1, 32, kernel_size=3, stride=2, padding=1), # 32x14x14
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1), # 64x7x7
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Conv2d(64, 128, kernel_size=3, stride=2, padding=1), # 128x4x4
nn.BatchNorm2d(128),
nn.ReLU(),
)
# 全結合層で潜在空間へ
self.fc = nn.Linear(128 * 4 * 4, latent_dim)
def forward(self, x):
x = self.conv_layers(x)
x = x.view(x.size(0), -1) # Flatten
x = self.fc(x)
return x
# Decoderの定義
class Decoder(nn.Module):
def __init__(self, latent_dim):
super(Decoder, self).__init__()
# 潜在空間から特徴マップへ
self.fc = nn.Linear(latent_dim, 128 * 4 * 4)
# 転置畳み込み層(逆畳み込み)
self.deconv_layers = nn.Sequential(
# 入力: 128x4x4
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1), # 64x8x8
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, 32, kernel_size=4, stride=2, padding=1), # 32x16x16
nn.BatchNorm2d(32),
nn.ReLU(),
nn.ConvTranspose2d(32, 1, kernel_size=4, stride=2, padding=3), # 1x28x28
#nn.Tanh() # -1~1の範囲に出力
nn.Sigmoid() # 0-1の範囲に出力を制限
)
def forward(self, x):
x = self.fc(x)
x = x.view(x.size(0), 128, 4, 4) # Reshape
x = self.deconv_layers(x)
return x
# AutoEncoderの定義
class AutoEncoder(nn.Module):
def __init__(self, latent_dim):
super(AutoEncoder, self).__init__()
self.encoder = Encoder(latent_dim)
self.decoder = Decoder(latent_dim)
def forward(self, x):
latent = self.encoder(x)
reconstructed = self.decoder(latent)
return reconstructed
# モデルの初期化
model = AutoEncoder(LATENT_DIM).to(device)
# 損失関数と最適化手法
# criterion = nn.MSELoss() # 平均二乗誤差
# 損失関数(二値交差エントロピー)
criterion = nn.BCELoss()
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
# 訓練ループ
def train(model, train_loader, criterion, optimizer, epochs):
model.train()
losses = []
for epoch in range(epochs):
epoch_loss = 0
for batch_idx, (data, _) in enumerate(train_loader):
data = data.to(device)
# 勾配の初期化
optimizer.zero_grad()
# 順伝播
reconstructed = model(data)
# 損失計算
loss = criterion(reconstructed, data)
# 逆伝播
loss.backward()
# パラメータ更新
optimizer.step()
epoch_loss += loss.item()
if batch_idx % 100 == 0:
print(f'Epoch [{epoch+1}/{epochs}], Step [{batch_idx}/{len(train_loader)}], Loss: {loss.item():.4f}')
avg_loss = epoch_loss / len(train_loader)
losses.append(avg_loss)
print(f'Epoch [{epoch+1}/{epochs}], Average Loss: {avg_loss:.4f}')
return losses
# 訓練実行
losses = train(model, train_loader, criterion, optimizer, EPOCHS)
# 結果の可視化
def visualize_results(model, test_loader, num_images=10):
model.eval()
with torch.no_grad():
data, _ = next(iter(test_loader))
data = data[:num_images].to(device)
reconstructed = model(data)
# CPU に移動して表示
data = data.cpu()
reconstructed = reconstructed.cpu()
fig, axes = plt.subplots(2, num_images, figsize=(15, 3))
for i in range(num_images):
# 元画像
axes[0, i].imshow(data[i].squeeze(), cmap='gray')
axes[0, i].axis('off')
if i == 0:
axes[0, i].set_title('Original', fontsize=10)
# 再構成画像
axes[1, i].imshow(reconstructed[i].squeeze(), cmap='gray')
axes[1, i].axis('off')
if i == 0:
axes[1, i].set_title('Reconstructed', fontsize=10)
plt.tight_layout()
plt.savefig('autoencoder_results.png')
plt.show()
# テストデータで可視化
test_dataset = datasets.MNIST(
root='~/.pytorch/data',
train=False,
download=True,
transform=transform
)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
visualize_results(model, test_loader)
# 損失の推移をプロット
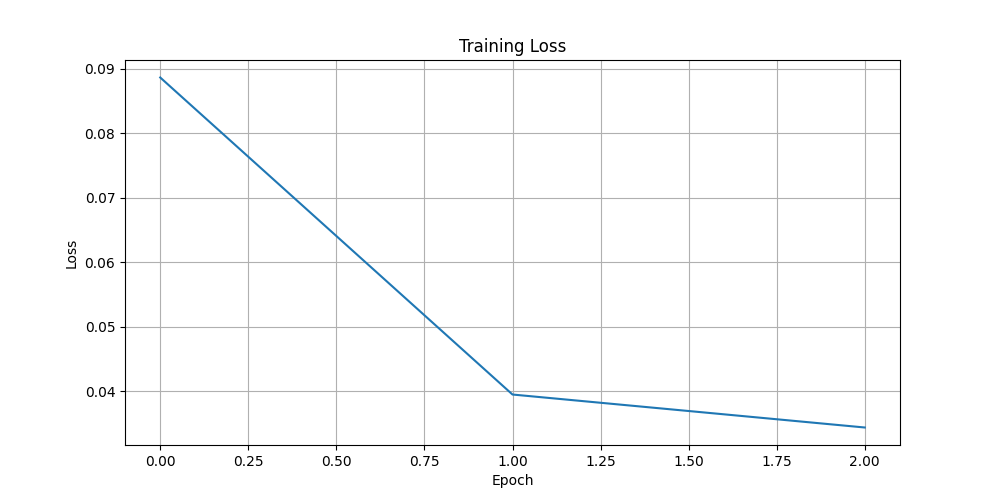
plt.figure(figsize=(10, 5))
plt.plot(losses)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training Loss')
plt.grid(True)
plt.savefig('autoencoder_loss.png')
plt.show()
主要部分の解説
1. Encoder(符号化器)
nn.Conv2d(1, 32, kernel_size=3, stride=2, padding=1)
- 畳み込み層で画像の特徴を抽出
stride=2で画像サイズを半分に縮小- 徐々にチャネル数を増やして特徴を豊かに
2. Decoder(復号化器)
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1)
- 転置畳み込みで画像を拡大
- Encoderの逆操作を実行
- 最終的に元の画像サイズに復元
3. 損失関数
criterion = nn.MSELoss()
- 元画像と再構成画像の差を最小化
- 二値画像には
BCELossも使用可能
このコードを実行すると、画像の圧縮・復元が学習され、ノイズ除去や特徴抽出にも応用できます。
4. 実行の結果
% python3 binary-image-cnn-autoender.py
Epoch [1/3], Step [0/469], Loss: 0.5709
Epoch [1/3], Step [100/469], Loss: 0.1056
Epoch [1/3], Step [200/469], Loss: 0.0652
Epoch [1/3], Step [300/469], Loss: 0.0550
Epoch [1/3], Step [400/469], Loss: 0.0507
Epoch [1/3], Average Loss: 0.0886
Epoch [2/3], Step [0/469], Loss: 0.0445
Epoch [2/3], Step [100/469], Loss: 0.0387
Epoch [2/3], Step [200/469], Loss: 0.0380
Epoch [2/3], Step [300/469], Loss: 0.0394
Epoch [2/3], Step [400/469], Loss: 0.0358
Epoch [2/3], Average Loss: 0.0395
Epoch [3/3], Step [0/469], Loss: 0.0347
Epoch [3/3], Step [100/469], Loss: 0.0362
Epoch [3/3], Step [200/469], Loss: 0.0373
Epoch [3/3], Step [300/469], Loss: 0.0373
Epoch [3/3], Step [400/469], Loss: 0.0351
Epoch [3/3], Average Loss: 0.0344
5. 元画像と再構成画像
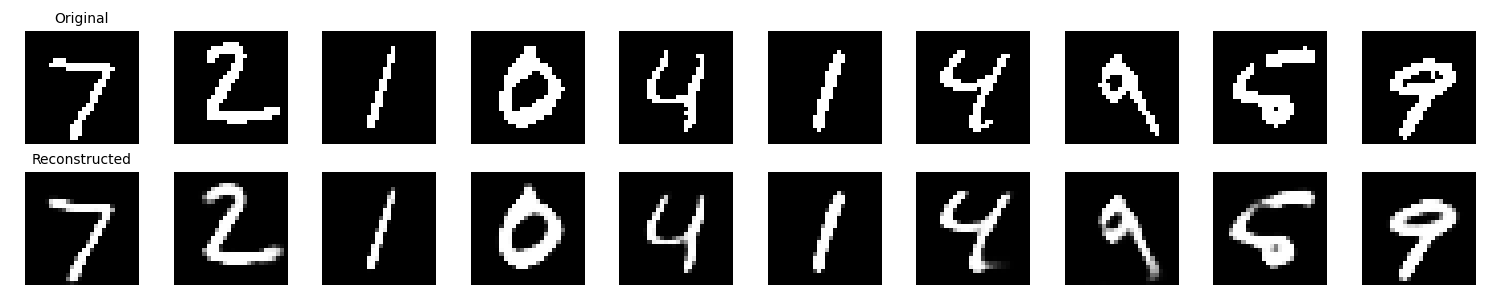
6. 損失の推移